
The Ultimate Guide to Context Engineering for PMs
All the frameworks, prompts, and checklists you need to master context engineering - from an OpenAI Product Leader


AI product building is a rich man and a poor man’s game.
On the rich man’s side…
The chips have never been more powerful, the models have never been more capable, and the barrier to building AI features has never been lower.
On the poor man’s side…
Most AI features shipped today still behave like interns. Let’s be honest. They’re good in certain use cases. But they need hand holding. And they’re inconsistent.
Why?
The answer is rarely “model quality.” It is almost always context quality.
That’s why “context engineering” sounds like an engineering topic, but it is one of the most important disciplines for AI PMs.
World-Class AI leaders Agree
Here’s Tobi Lutke, CEO of Shopify:

And Andrej Karpathy, OpenAI Co-Founder and former head of Tesla Autopilot:

They both are echoing the importance of this skill. So I expected to find lots of great content out there.
Surprisingly, all the other content I found was geared to AI engineers, not AI PMs.
So I wanted to create the ultimate guide for PMs.
Side Note: If you want to go beyond just context engineering and master how to build enterprise level AI Products from scratch from OpenAI’s Product Leader, then our #1 AI PM Certification is for you.
3,000+ AI PMs graduated. 750+ reviews. Click here to get $500 off. (Next cohort starts Jan 26)

Today’s Post

Why Does Context Engineering Matter?
The PM’s Role in Context Engineering
The 6 Layers of Context to Include
Common Mistakes
How to Engineer Context Step-by-Step
How to Spec out Features Appropriately
Checklists, templates + prompts you can steal
1. What is Context Engineering, and Why Does it Matter?
Defining Context Engineering
We like Andrej’s definition from above. Context engineering is:
The delicate art and science of filling the context window with just the right information for the next step.
If prompt engineering is the instruction sheet, context engineering is the entire world the model sees.
As Ilya Sutskever (another OpenAI founder) highlighted in the recent Dwarkesh podcast, the big difference between humans and LLMs is LLMs do not infer context magically. They do not automatically know:
who the user is
what the user did 5 seconds ago
which document is relevant
what the system knows about the user
what rules the business must follow
what data is allowed to be used
what happened in previous sessions
whether the user is a beginner or an expert
which constraints must be met
which entities exist in the user’s workspace
how everything relates to everything else
That’s what we’re going to put in with context engineering.
Why Context Engineering Matters
Everyone wants to talk about model selection and prompts.
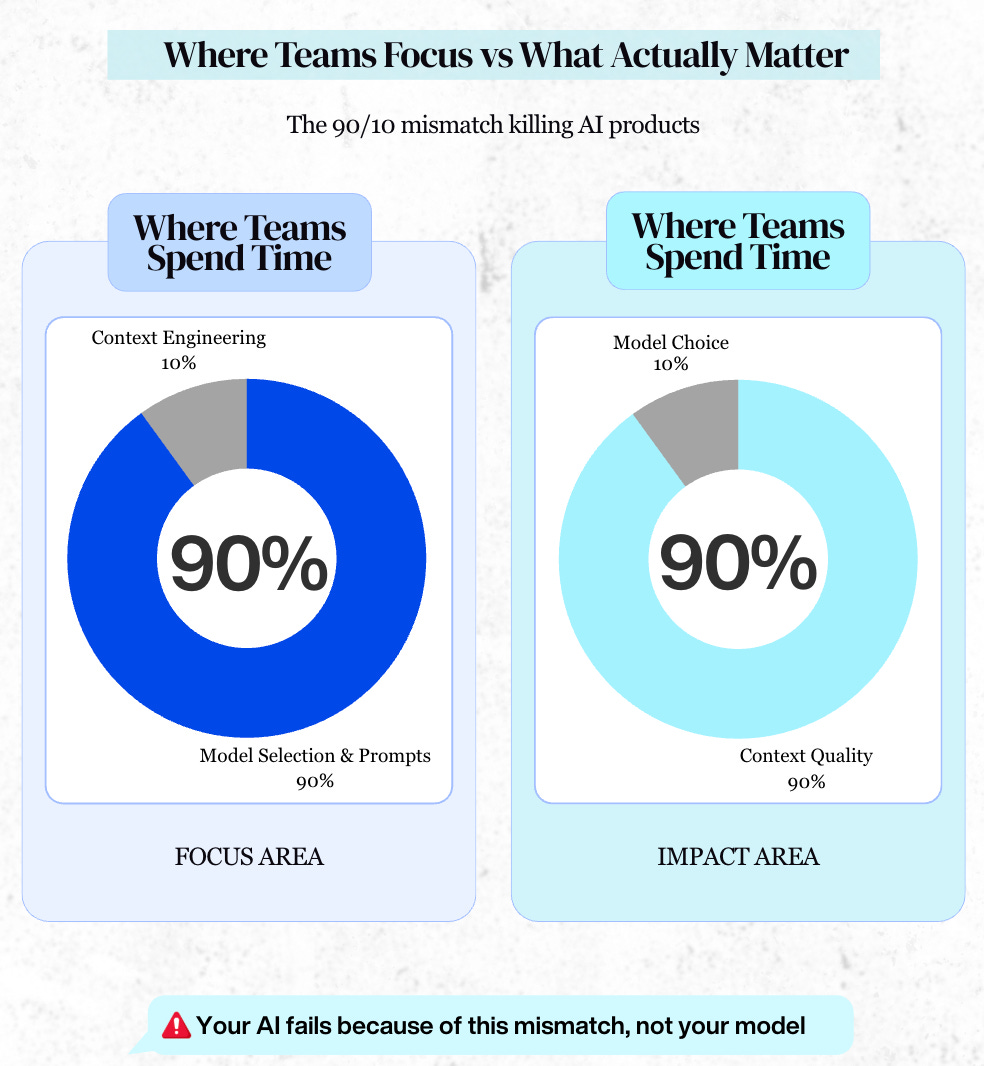
You can switch from GPT-5.1 to Gemini 3. But, if the system:
doesn’t know what file the user is working on
doesn’t see the user’s preferences,
isn’t aware of the entities or relationships in the workspace,
cannot recognize the user’s role,
retrieves irrelevant documents,
or misses crucial logs…
Then you’re SOL (shit outta luck).
Here’s 2 real life examples:
Example 1: AI Email Assistants
When we were building Apollo’s email writer, Aakash learned that when the model sees:
We only gave it the last message → output was generic
We gave it the entire thread → output became coherent
We gave it the thread + CRM notes → output became personalized
We gave it thread + CRM + company tone-of-voice → output became brand aligned
We gave it thread + CRM + tone + relationship context → the output became shippable
It encoded the importance of context engineering in my mind.
Example 2: AI Coding Assistants
Let’s take another example. Do a thought exercise: How has Cursor managed to not get replaced with Anthropic and hit $1B ARR?
— WAIT FOR IT —
— DON’T READ AHEAD TILL YOU THINK ABOUT IT —
Our answer?
When you open a project in Cursor, it indexes your codebase by computing embeddings for each file, splitting code into semantically meaningful chunks based on the AST structure.
When you ask a question, it converts your query into embeddings, searches a vector database, retrieves the relevant file paths and line numbers, then adds that content to the LLM context.
This is why Cursor lets you choose between models from OpenAI, Anthropic, Gemini, and xAI. The model is almost modular. The context layer is the moat.
Google tried to buy Cursor instead of compete. When that failed, they spent $2.4B on Windsurf, the #2 player.
That’s a signal that context engineering creates defensibility that model capability alone cannot replicate.
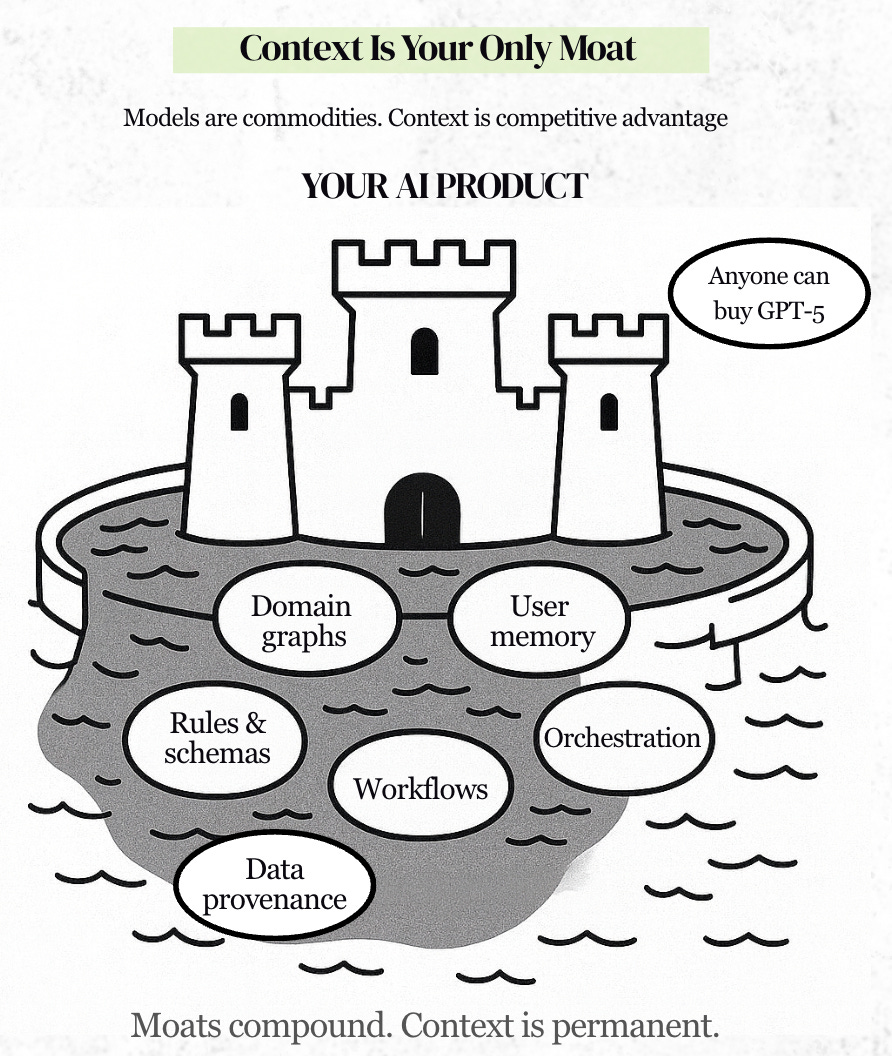
So now that you understand why context engineering is your moat, we’re going to give you every tactical tool to do it well: frameworks and canvases to use as a PM + real life checklists, templates & prompts you can steal. It’s easily the deepest guide for AI PMs on the web.
2. The PM’s Role in Context Engineering
Most teams assume context engineering is an engineering problem.
It is not.
Context engineering sits at the intersection of product strategy, user understanding, and system design. Engineers can build the infrastructure, but they cannot decide what context matters, why it matters, or how it should shape user experience.
That requires product judgment.
What PMs Own in Context Engineering
As a PM, you own three critical layers that engineers cannot:
1. Defining what “intelligence” means for your feature
Before any code is written, you must specify exactly what success looks like:
What should the AI know about the user?
What domain knowledge is essential versus nice-to-have?
Which user actions should trigger context updates?
What level of personalization creates value without feeling creepy?
These are product decisions, not technical ones.
2. Mapping the context requirements to user value
You translate fuzzy user needs into specific context specifications:
“Users want better suggestions” becomes “the system needs access to past rejections, current workspace state, and team preferences”
“Make it feel personalized” becomes “capture user’s writing style, common corrections, and role-specific patterns”
Engineers need this translation layer. Without it, they build generic systems that technically work but feel hollow.
3. Designing the degradation strategy
When context is missing, stale, or incomplete, someone must decide how the feature should behave. This is pure product work:
Do we block the feature entirely?
Show a partial answer with caveats?
Ask clarifying questions?
Fall back to a simpler, non-personalized response?
These decisions determine whether users trust your AI or abandon it.
What Engineers Own
Engineers own the implementation: retrieval architecture, vector databases, embedding pipelines, API integrations, performance optimization, and system reliability.
But they need you to define the “what” and “why” before they can build the “how.”
The Division of Labor
Think of it this way:
PMs define the context pyramid (what goes in each layer)
Engineers build the context infrastructure (how to fetch and store it)
PMs design the orchestration logic (what the model sees when)
Engineers implement the orchestration engine (the system that executes it)
When PMs skip their role, engineering teams build technically impressive systems that feel unintelligent because nobody specified what intelligence actually requires.
3. The 6 Layers of Context to Include
If you look closely at every world-class AI product, you’ll find their intelligence doesn’t come from clever prompting or bigger models. It comes from a carefully engineered hierarchy of context.
Here are the six layers every AI system needs:

LAYER 1 - INTENT CONTEXT
Starting at the bottom…
Understanding what the user actually means, not what they literally typed.
Almost every catastrophic AI failure (hallucinations, wrong answers, irrelevant reasoning, misaligned suggestions) can be traced back to one root cause: the system misunderstood the user’s true intent. Humans speak imprecisely.
They request one thing while meaning another. They highlight text instead of explaining what the problem is. They click, hesitate, undo, rephrase, or issue half-statements filled with assumptions the model cannot see.
That is why Intent Context exists: to build the AI’s interpretive intelligence: the ability to reconstruct what the user is truly trying to do even when the request is ambiguous, underspecified, or emotionally framed.
The Triple-I Intent Framework
To make intent context operational rather than philosophical, every AI system must run incoming input through a three-step mental model:
Interpret: Translate the explicit text into a structured task objective.
Infer: Use recent user behavior (selections, hovered components, edited text, recent failures) to uncover hidden meaning behind the request.
Identify Gaps: Detect missing information the system must retrieve before reasoning (e.g., relevant files, recent code changes, metric definitions).
This transforms user input into a machine-actionable intent, turning ambiguity into clarity and enabling the next five layers to function correctly.
LAYER 2 — USER CONTEXT
A continuously updated portrait of the individual: their patterns, preferences, behaviors, and cognitive style.
Even the most correct output can feel wrong if it is not personalized.
A senior engineer expects a surgical diff; a beginner wants a detailed walkthrough.
A founder wants executive-level brevity; a student wants scaffolding and structure.
User Context exists so the AI can operate not as a generic assistant but as a personal cognitive extension of the individual — adapting seamlessly to their style, tone, pacing, skill level, and historical decisions.
The 5-P Personalization Matrix
To make personalization tangible, store these five dimensions for each user:
Preferences: Tone (concise, formal, friendly), depth, writing voice.
Patterns: Common edits, recurring corrections, formatting habits.
Proficiency: Beginner, intermediate, expert (auto-adjust the complexity).
Pacing: How fast the user consumes or expects answers.
Purpose: Their role-specific motivations and workflows.
This gives your AI the ability to answer in the user’s voice, not the model’s.
LAYER 3 — DOMAIN CONTEXT
Without domain grounding, an AI system is not a product, it is a hallucination machine covered in UX polish.
Domain Context is what turns your AI from a generative toy into a factual expert, capable of referencing real objects, understanding dependencies, using proper definitions, and navigating your internal world with confidence.
It is everything the system must treat as law: your entities, metadata, relationships, processes, codebase, documents, metrics, business rules, historical decisions, and institutional memory. But for this to work, domain knowledge cannot live as blobs of text — it must be structured.
Every domain must be represented through five structural pillars:
Entities: The objects in your world: tasks, metrics, PRs, dashboards, users, components.
Attributes: The metadata fields that describe them: owners, timestamps, tags, versions.
Relationships: The connections: “depends on,” “caused by,” “related to,” “belongs to.”
Definitions & Rules: Canonical metric definitions, formulas, and business logic.
Lineage: The version history and provenance of every object.
LAYER 4 — RULE CONTEXT
The boundaries, constraints, permissions, policies, and formats that govern what the AI may or may not do.
Even the smartest system becomes dangerous in the absence of rules. Rule Context serves as the judicial system of your AI: the governing body that determines what is allowed, what is forbidden, what must be enforced, what must be formatted precisely, and what must never be violated.
This includes everything from safety and compliance to output schemas, permission models, prohibited actions, and formatting rules. And rules must not be suggestions buried in prompts — they must be enforceable boundaries.
The Two-Wall Constraint Framework
Implement rule context through two kinds of walls:
The Soft Wall: advisory constraints (tone, brand, voice, style, preferences).
The Hard Wall: mandatory constraints (schemas, validation, permissions, safety, compliance).
Soft walls shape behavior.
Hard walls enforce correctness.
Together, they transform your AI from probabilistic improviser into deterministic operator.
LAYER 5 — ENVIRONMENT CONTEXT
The real-time conditions shaping the user’s world in this exact moment.
Nearly all user tasks depend on the present situation, not static knowledge.
A code assistant must know which file is open.
A writing assistant must know which paragraph is selected.
A dashboard assistant must know which metric failed in the last hour.
A planning assistant must know the upcoming deadline.
Environment Context injects situational intelligence into the AI… giving it awareness of the current file, current selection, current timestamp, current errors, current tool outputs, and current workflow.
The N.O.W. Awareness Model (Actionable Implementation)
Capture real-time signal through three dimensions:
Nearby Activity: What the user is interacting with right now (highlight, cursor, file).
Operational Conditions: Logs, recent errors, system state, device context.
Window of Time: Deadlines, timestamps, recency signals.
This allows the AI to act not generically but contextually like a colleague who is watching the screen at the same moment you are working.
LAYER 6 — EXPOSITION CONTEXT
The final, distilled, structured, contradiction-free packet of meaning the model actually sees.
This is the summit of the pyramid — the moment where the system assembles everything from the previous five layers into a refined, clean, hierarchical, relevance-ranked, noise-filtered payload that becomes the AI’s cognitive workspace.
The exposition layer is where intelligence becomes execution.
It is the difference between giving the model the entire haystack and giving it exactly the right needle.
The Context Distillation Loop (Actionable Implementation)
Every context packet must go through a five-step purification cycle:
Collect: Gather all relevant intent, user, domain, rule, and environment signals.
Compress: Remove noise, collapse redundancy, clean contradictions.
Construct: Organize the final payload into labeled sections with clear boundaries.
Constrain: Apply rules, schemas, safety boundaries, and formatting requirements.
Check: Validate internal consistency and readiness for LLM reasoning.
Making the Layers Work Together
When all six layers work together, the AI finally becomes intelligent. Most teams skip layers or implement them shallowly. The best teams treat each layer as essential infrastructure, not optional polish.
4. Common Mistakes in Context Engineering
When you examine AI systems that consistently deliver high-quality, contextual assistance, they all follow similar patterns. When you examine AI systems that hallucinate, drift, or confuse users, they make the same mistakes.
Here’s what separates great context engineering from broken implementations.
What Great AI Products Do Right
The strongest AI products almost always follow these patterns:
Context is never raw; it is always structured. Teams create schemas, metadata fields, entity types, and relationship graphs because they understand that unstructured blobs lead to unstructured behavior.
Context is curated rather than dumped. The system does not “give the model everything”; instead, it pre-filters aggressively, selecting only the signals that materially affect reasoning.
Context is layered rather than flattened. The best systems separate immediate intent (Layer 1), session memory (Layer 2), long-term memory (Layer 3), domain knowledge (Layer 4), rules (Layer 5), and environment signals (Layer 6), feeding each into the model in a predictable order.
Models receive context in labeled sections. Everything is wrapped in explicit headers like “Relevant History,” “User Preferences,” “Domain Constraints,” “Entities,” and “Latest Logs,” to reduce ambiguity.
Domain knowledge is treated as a living graph rather than a static index. Every new artifact introduces new relationships, creating a continuously evolving network of meaning.
Rules are enforced outside the model. Hard constraints are applied via validators, schemas, and business logic rather than being stuffed into prompts.
Context generation is multi-step. The system uses planning calls, intermediate reasoning, summarization steps, and iterative refinement rather than one giant LLM call.
What Breaks AI Systems
The AI systems that routinely fail exhibit an equally predictable set of mistakes. Across hundreds of teams, these failure modes appear consistently:
“Just put everything in the prompt.” This creates token overload, model confusion, and inconsistent behavior.
Relying solely on semantic search. RAG without domain structure retrieves irrelevant chunks that distort reasoning.
Assuming prompts are enough to enforce rules. Prompts are not hard boundaries; they are suggestions. The model will eventually ignore them.
Treating context engineering as an afterthought. Teams that wait until the end to define schemas, metadata, and rules inevitably ship weak AI features that cannot grow.
Mixing raw and enriched context. Blending unstructured text with structured representations causes contradictions and hallucinations.
Not maintaining provenance. When the model doesn’t know where a piece of information came from, it becomes impossible to reason reliably.
Trusting the model to “figure out the structure.” No matter how sophisticated an LLM is, it will never infer your domain schema unless you explicitly define it.
The Pattern
Good context engineering requires discipline. It means saying no to shortcuts, investing in structure upfront, and treating context as the foundation of intelligence rather than an afterthought.
5. How to Engineer Context Step-by-Step
The previous section showed you what context to include. This section shows you how to actually build the machinery that makes it work.
Nearly every AI feature that feels “smart” has an invisible three-stage process operating beneath it. The system captures raw signals, enriches them into structured meaning, then orchestrates what the model actually sees.
This is the C.E.O. Framework: Capture, Enrich, and Orchestrate.
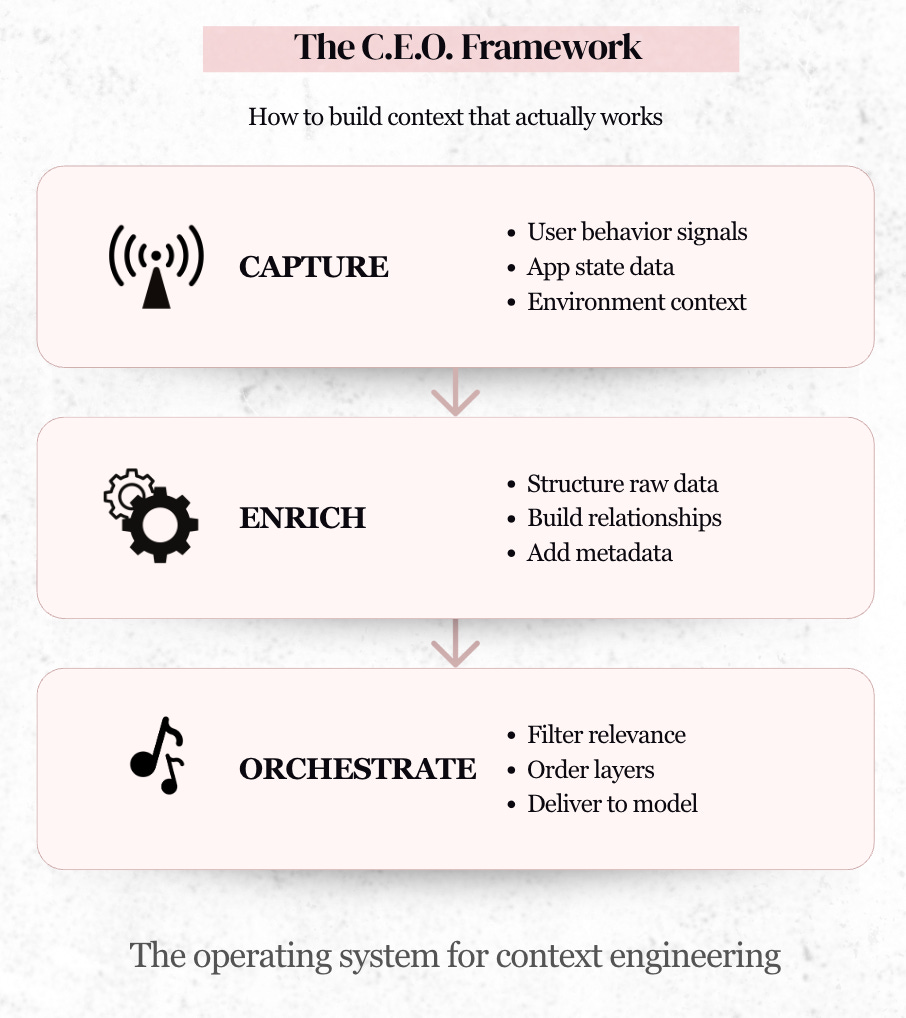
CAPTURE — How an AI System Absorbs the World
“Capture” is the foundational act of noticing – the process of collecting the raw ingredients of intelligence from user behavior, application state, domain artifacts, and the external environment.
If an AI system behaves like a human interlocutor with awareness, intuition, and relevance, it is because the Capture layer is continuously gathering dozens of micro-signals that enable the system to understand not just what the user said, but what the user meant, what the user is doing, what the user is looking at, what the system knows, and what the situation demands.
In high-quality AI products, the capture layer does not wait for the user to explicitly provide context; instead, it silently observes everything that meaningfully shapes the user’s intent:
The document currently open
The text they highlighted
The field they recently edited
The filter they applied
The last action they took
The segment they drilled down into
The item they clicked
The last output they accepted or rejected
The deadlines looming on their timeline
And countless other subtle signals that collectively paint a picture far richer than any prompt the user could ever type manually.
A well-designed capture layer combines three large families of inputs:
A. explicit signals, such as prompts or selections
B. Implicit signals, such as scroll patterns, cursor behavior, or recent interactions
C. System-generated signals, such as timestamps, object metadata, analytics freshness, or current environment state
And transforms this ongoing stream of micro-data into a coherent understanding of what matters right now!
ENRICH — How Raw Signals Become Structured Meaning
Enriching context means converting raw, unstructured, ambiguous, or incomplete signals into structured, meaningful, and model-ready representations of the world. Turning the messy, lived complexity of a user’s environment into a consistent schema the model can reliably reason about.
Enrichment is where the system extracts entities from documents, identifies relationships between objects, interprets timestamps in context, normalizes fields across multiple sources, resolves ambiguity, infers missing information, filters irrelevant data, consolidates redundant information, embeds content for retrieval, annotates objects with domain metadata, connects artifacts into graph structures, and ultimately produces a structured “context package” that faithfully captures the reality the model needs to reason about.
This process is not trivial; enrichment requires careful engineering because it must handle edge cases elegantly.
Two documents may describe the same entity differently:
1. Two users may interpret the same phrase with different meanings
2. A user may refer to “the latest version” of a document without specifying which one; a metric may have updated since the last time the user viewed it
3. A product may have changed its state due to unrelated events outside the user’s current workflow
An AI system must reconcile all of these variations into one coherent representation before generating an answer.
A sophisticated enrichment pipeline performs tasks like disambiguating references (“this issue,” “that customer,” “the last update”)...
Stitching together related objects (“this PR is related to that incident”)...
Reconstructing implied relationships (“the user selected a risk, which implies a focus on the project’s risk matrix”)
And augmenting context with domain knowledge (“this metric depends on that event stream, which was updated four hours ago”).
ORCHESTRATE — How the System Decides What the Model Should Actually See
Orchestration is judgment: the deliberate decision-making process that determines which pieces of context the model should receive, in what order, at which level of detail, and in what representation format.
Orchestration is where context engineering becomes an art form, because feeding an LLM too much information confuses it, feeding it too little misleads it, feeding it irrelevant data distracts it, and feeding it the wrong structure causes unpredictable behavior.
Orchestration must balance four competing forces at once:
Relevance, ensuring the model sees only what materially affects the user’s request
Brevity, ensuring the context fits within token limits without sacrificing meaning
Precision, ensuring the context is clearly structured so the model can use it effectively
Timing, ensuring the right information reaches the model at the right moment in multi-step interactions.
This stage involves selecting the most relevant artifacts from the domain graph, filtering out stale or irrelevant objects, choosing the correct segments of documents rather than entire documents, resolving conflicts when multiple sources offer overlapping information, determining whether to provide summaries or raw text, deciding when to call retrieval systems, choosing whether the model needs a planning step before final generation, and enforcing ordering rules so that constraints and instructions appear in the right place relative to the task description.
A strong orchestration architecture explicitly separates concerns: one layer determines which context to include; another layer structures it into clearly labeled sections; another layer embeds rules and constraints; another layer attaches user preferences and long-term history; and another layer controls the multi-step flow if multiple LLM calls are needed.
This creates a stable, predictable ecosystem where context is not a random blob of text but a deliberate, coherent, and highly curated dataset designed specifically for the model to reason effectively.
6. How to Spec out Features Appropriately
You now have the Context Pyramid (the six layers of context) and the C.E.O. Framework (how to operationalize context at runtime).
But when you sit down to spec your next AI feature, you need something different: What context does this feature require? How will we get it? What happens when it breaks?
That is what the 4D Context Canvas solves.
The Pyramid gives you the categories. C.E.O. gives you the engine. The Canvas gives you the feature-level plan.
The truth is that most AI features fail long before they ever reach the model.
They fail because teams never wrote down the context the model would need to succeed.
They fail because teams relied on assumptions like “we can fetch that,” “the model will figure it out,” or “the data probably exists.”
In reality, AI features collapse for four predictable reasons:
Nobody defined the model’s actual job. Developers write prompts, not job specifications, leaving the system to guess the real objective.
Nobody mapped the context the model will require. Features assume context exists without verifying source, reliability, or structure.
Nobody identified how context would be discovered at runtime. Features depend on data that may not be fetchable, indexable, or even stored anywhere.
Nobody designed defenses for when the context is wrong, missing, stale, or misleading. AI features operate as if everything will be perfect on the first try, an illusion that shatters immediately in production.
The 4D Context Canvas solves all of this by forcing the team to explicitly specify:
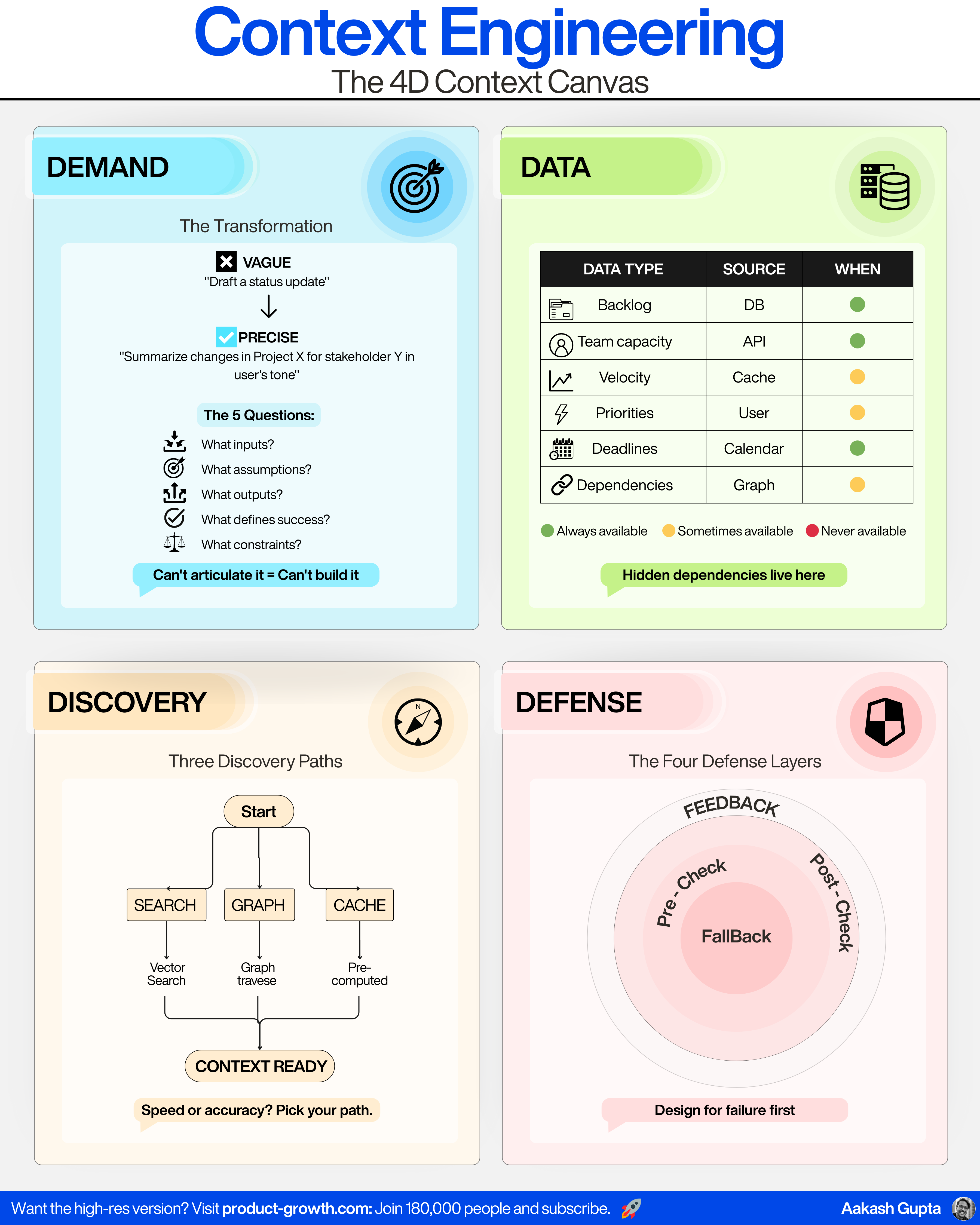
Demand: What is the model actually being asked to do?
Data: What context is required to get it right?
Discovery: How will we obtain that context reliably during runtime?
Defense: How will we detect failures and prevent incorrect outputs?
D1 — DEMAND: DEFINING THE MODEL’S JOB PRECISELY
If you cannot articulate the model’s job, the model cannot do it.
The first and most important part of building an AI feature is translating a fuzzy product requirement into a precise, narrowly scoped model job.
When PMs skip this step, AI features become unpredictable, generic, or oblivious to the actual objective. The key is to rewrite the feature goal in a way that clarifies:
What the model must produce
For whom
Under what assumptions
Using which constraints
In what format
With what definition of success
The transformation looks like this:
“Draft a status update” becomes: “Summarize the key changes in project X since the last report, structured for stakeholder Y, using the user’s preferred tone, while adhering to the product’s reporting format.”
A proper model job spec contains:
Inputs: What the model will receive
Assumptions — What we know, what we don’t, and what defaults we apply
Required Outputs — Format, structure, constraints, tone
Success Criteria — What defines “good” versus merely “acceptable”
D2 — DATA: MAPPING THE CONTEXT REQUIREMENTS
Every AI feature has hidden dependencies, this step makes them visible.
Once the model’s job is defined, the next step is specifying the exact context the model will need to do that job correctly. This requires creating a Context Requirements Table, a simple but powerful layout that removes ambiguity about what data the system must provide to the model.
The Context Requirements
Each describes one required piece of context.
Data Needed: The entity, document, metric, object, or signal the model depends on
Source: Where it lives (DB, API, logs, cache, knowledge graph, user input)
Availability:
Always (can be fetched 100% of the time)
Sometimes (depends on user actions or data freshness)
Never (must be requested explicitly or cannot be assumed)
Sensitivity: PII, internal-only, restricted, public
Example for an AI Sprint Planning Assistant:
Backlog items
Team capacity
Historical velocity
Priority constraints
Deadlines
Cross-team dependencies
When you map this table honestly, you discover quickly whether the feature is feasible, risky, or missing critical data pipelines.
D3 — DISCOVERY: RUNTIME CONTEXT DISCOVERY STRATEGY
Knowing what data you need is not the same as knowing how to get it.
The third D is where most AI features break. It is one thing to list the data you need; it is another to reliably fetch it when the user triggers the feature.
Discovery defines how the system will locate, retrieve, infer, or generate the required context during live, real-time execution.
Discovery involves several strategies:
Search-Based Retrieval
Vector search for semantic similarity
Keyword search for precision
Hybrid search for reliability
Graph-Based Traversal
Following relationships through a knowledge graph
Navigating from the “starting entity” to related objects
Precomputed Context
Daily/weekly jobs that populate caches
Materialized views for expensive queries
Pre-generated candidates for high-latency features
Latency vs. Quality Trade-offs
Teams must decide:
Which context must be real-time?
Which can be precomputed?
Which can degrade gracefully?
A feature only works reliably when discovery is engineered with the same precision as intent and data mapping.
D4 — DEFENSE: GUARDRAILS, FALLBACKS, AND FEEDBACK
The feature is not complete until you’ve designed how it fails.
Defense is the layer that turns an AI demo into an AI system.
Because AI will fail.
Context will be missing.
Data will be stale.
Sources will be unavailable.
The model will hallucinate confidently.
Defense is about detecting and correcting failures before the user sees them.
There are four categories of defense mechanisms:
1. Pre-Checks
Before calling the model, the system evaluates:
“Do we have enough context to answer?”
“Are required entities missing?”
“Is the data too old or incomplete?”
If not, the system should block generation or trigger a clarification question.
2. Post-Checks
After generation, the system validates:
Did the answer follow constraints?
Is it logically consistent?
Does it violate any rule or policy?
Does it match required schemas?
3. Fallback Paths
When things break, the system must degrade gracefully:
Partial answer with notes
Clarifying questions
Conservative defaults
Safe summaries instead of imaginative claims
4. Feedback Loops
The feature improves through:
Explicit ratings
Implicit behavior (user undo, edits, corrections)
Pattern detection across mistakes
In short…
Demand tells you what the model must do.
Data tells you what the model must consume.
Discovery tells you how to find that data.
Defense tells you how to prevent failure.
7. Checklists, templates, and prompts you can steal
The Context Quality Checklist
Use this every single time before sending anything to an LLM.
This checklist ensures your context isn’t noisy, stale, missing, contradictory, or over-stuffed because all hallucinations are context failures long before they are model failures.
RELEVANCE CHECK
Does every piece of context directly contribute to answering the user’s intent?
Did you remove everything “kind of related” but not essential?
Did you strip decorative metadata that confuses the model?
FRESHNESS CHECK
Are all timestamps recent enough for this task?
Are metrics, logs, and dashboards updated?
Are cached artifacts invalid for this request?
SUFFICIENCY CHECK
Did you include all entities the model needs to reason correctly?
Did you provide the necessary related objects (e.g., dependencies, history)?
Does the model have enough context to avoid hallucinating missing links?
STRUCTURE CHECK
Is your context broken into clean sections with clear labels?
Are relationships explicitly described rather than implied?
Is all domain knowledge structured instead of dumped?
CONSTRAINT CHECK
Did you embed business rules explicitly?
Did you include tone requirements, formatting rules, and domain rules?
Is permission logic represented accurately?
This checklist ensures the “brains” of your system are always fed clean signals.
The Orchestrator Context Prompt
This is the template underlying high-quality reasoning, allowing the LLM to work with clarity rather than noise.
[System Instructions]
You are an AI assistant operating inside a structured context engine.
Follow all business rules, domain constraints, and formatting instructions exactly.
Do not invent facts outside the provided context.
[User Intent]
{inferred_intent}
{explicit_prompt}
[Relevant Entities]
{structured_entities}
[Relationships]
{entity_relationships}
[Session State]
{recent_messages}
{recent_selections}
[User Profile]
{role}
{tone_preferences}
{writing_style}
{prior_examples}
[Domain Context]
{retrieved_docs}
{summaries}
{attached_metadata}
[Rules & Constraints]
{business_rules}
{policies}
{formatting_requirements}
{prohibited_actions}
[Environment Signals]
{calendar_events}
{deadlines}
{system_status}
{device_context}
[Task Instructions]
Clear, step-by-step instructions for what the model must produce.
[Output Schema]
{json_schema_or_output_structure}This template alone reduces hallucinations by 70%+ in real systems.
Here’s an example for you:
[System Instructions]
You are an AI assistant operating inside a structured context engine for a product team.
You write weekly product status updates for senior stakeholders (VP Product, CTO, CEO) based strictly on the context provided below.
You must:
- Follow all business rules, domain constraints, and formatting instructions exactly.
- Never invent projects, metrics, incidents, or timelines that are not explicitly present in Domain Context, Relevant Entities, Relationships, or Session State.
- Treat the Domain Context and Rules & Constraints sections as the single source of truth.
- If critical information is missing, you must clearly state what is missing instead of guessing.
[User Intent]
{inferred_intent}:
“Summarize the most important product changes, progress, risks, and next steps for the past week into an executive-ready weekly update.”
{explicit_prompt}:
“Can you draft this week’s product update for leadership based on what changed since last Monday?”
[Relevant Entities]
{structured_entities}:
- project_roadmap_item:
id: “PRJ-142”
title: “Onboarding Funnel Revamp”
owner: “Sara”
status: “In Progress”
target_release: “2025-12-01”
- project_roadmap_item:
id: “PRJ-087”
title: “AI Assistant v2”
owner: “Imran”
status: “Shipped”
target_release: “2025-11-15”
- metric:
id: “MTR-DAU”
name: “Daily Active Users”
current_value: 18240
previous_value: 17680
unit: “users”
- incident:
id: “INC-221”
title: “Checkout Latency Spike”
status: “Resolved”
severity: “High”
[Relationships]
{entity_relationships}:
- “PRJ-142” depends_on “PRJ-087”
- “INC-221” impacted “checkout_conversion”
- “MTR-DAU” improved_after “AI Assistant v2” release
- “PRJ-087” linked_to_release “2025.11.15-prod”
[Session State]
{recent_messages}:
- 2025-11-17T09:03Z – User: “Last week’s update is in the doc; I want something similar but shorter.”
- 2025-11-17T09:04Z – Assistant: “Understood, I will keep a similar structure but be more concise.”
- 2025-11-17T09:06Z – User: “Don’t oversell wins; keep it realistic.”
{recent_selections}:
- User highlighted last week’s “Risks & Blockers” section.
- User opened the “AI Assistant v2 – Launch Notes” document.
- User clicked on metrics dashboard filtered to “Last 7 days”.
[User Profile]
{role}:
- “Director of Product, responsible for AI & Growth initiatives.”
{tone_preferences}:
- Confident but not hype.
- Data-informed, not overly narrative.
- Clear separation of “What happened”, “Why it matters”, and “What’s next”.
{writing_style}:
- Short paragraphs.
- Uses headers and subheaders.
- Uses occasional bullet points for clarity, but avoids long bullet lists.
- Avoids exclamation marks and marketing language.
{prior_examples}:
- Example snippet of previous accepted update:
“This week we completed the rollout of the new onboarding experiment to 50% of new users. Early results show a +3.2% lift in activation. Next week we’ll either scale this to 100% or roll back depending on retention impact.”
[Domain Context]
{retrieved_docs}:
- “Weekly Update – 2025-11-10” (last week’s product update)
- “AI Assistant v2 – Launch Notes”
- “Onboarding Funnel – Experiment Spec v3”
- “Incident Report – INC-221 Checkout Latency”
{summaries}:
- Last Week’s Update Summary:
“Focused on preparing AI Assistant v2 launch, mitigating checkout latency incidents, and kicking off onboarding experiment planning.”
- AI Assistant v2 Launch Notes Summary:
“Shipped on 2025-11-15 to 100% of users, goals: improve task completion speed and increase DAUs among power users.”
- Onboarding Funnel Spec Summary:
“Experiment targeting first session completion and activation, rollout to 25% → 50% cohorts, main success metric: day-3 activation.”
- Incident INC-221 Summary:
“High-severity latency issue, resolved within 4 hours, root cause was misconfigured database index on checkout service.”
{attached_metadata}:
- current_week_range: “2025-11-10 to 2025-11-17”
- timezone: “America/Los_Angeles”
- environment: “Production”
- product_area_focus: [”Onboarding”, “AI Assistant”, “Checkout”]
[Rules & Constraints]
{business_rules}:
- Do not share internal incident IDs in the update; describe incidents in business terms instead.
- Do not reference customers by name; aggregate or anonymize.
- Always tie product work back to business outcomes (activation, retention, revenue, support volume).
{policies}:
- No forward-looking commitments beyond what exists in the roadmap (no new promises).
- Do not mention unannounced features by name; use generic framing if needed.
- Maintain consistency with metric definitions (use official metric names only).
{formatting_requirements}:
- Structure the update into the following sections in this exact order:
1. Highlights
2. Metrics & Impact
3. Risks & Blockers
4. Next Week
- Use Markdown headings: H2 for main sections, bold for key terms.
- Keep total length under 600 words.
{prohibited_actions}:
- Do not fabricate metrics, dates, or launches.
- Do not mention any feature that is not explicitly referenced in Domain Context.
- Do not change the interpretation of metric names (e.g., DAU vs MAU).
[Environment Signals]
{calendar_events}:
- Today is Monday, 2025-11-17.
- The “Exec Product Sync” is scheduled for 2025-11-17 at 15:30 local time.
- This update is intended to be pasted into the agenda doc before that meeting.
{deadlines}:
- Q4 goals lock on 2025-12-01.
- Onboarding Funnel Revamp milestone review on 2025-11-25.
{system_status}:
- All systems operational.
- No open P0 incidents.
- Analytics data is fresh as of 2025-11-17T08:00Z.
{device_context}:
- User is currently on desktop web.
- Editing inside an internal docs tool with Markdown support.
[Task Instructions]
Using only the information provided above:
1. Draft a weekly product update that is realistic, grounded, and aligned with the user’s tone and prior examples.
2. Follow the required structure exactly: Highlights, Metrics & Impact, Risks & Blockers, Next Week.
3. Emphasize what actually changed this week compared to last week, not generic descriptions of projects.
4. Connect product work to business outcomes using the metric context provided.
5. Avoid exaggerating wins; if results are early or inconclusive, state that explicitly.
6. If there are known gaps in the context (e.g., missing metric results), note them transparently rather than inventing details.
[Output Schema]
{json_schema_or_output_structure}:
Return the final result as a JSON object with the following shape:
{
“highlights_markdown”: “string – Markdown-formatted section for Highlights”,
“metrics_and_impact_markdown”: “string – Markdown-formatted section for Metrics & Impact”,
“risks_and_blockers_markdown”: “string – Markdown-formatted section for Risks & Blockers”,
“next_week_markdown”: “string – Markdown-formatted section for Next Week”,
“notes_for_user”: “string – Any caveats, missing data notes, or assumptions you made”
}Final Words
We are now entering what will be remembered as the Age of Context.
In the early 2020s, AI products were “model-first,” built around clever prompts and demo-friendly outputs. They impressed audiences for a moment but disappointed them the second the tasks became real. Those systems are disappearing, and rightly so.
The next decade belongs to context-first AI systems: systems that understand users the way great colleagues do, systems that navigate institutional knowledge the way veterans do, systems that anticipate needs the way strategic thinkers do, and systems that follow rules the way regulated institutions require.
And unlike the fleeting advantage of a frontier model, which every competitor can simply buy or API-integrate, context is the only durable moat.
Your domain knowledge graph is a moat.
Your rules are a moat.
Your user memory is a moat.
Your workflows are a moat.
Your environment signals are a moat.
Your orchestration logic is a moat.
Your schemas are a moat.
Your data provenance is a moat.
And moats compound.
The teams who embrace context engineering today will build AI products that feel impossibly intelligent — not because they wait for the next model breakthrough, but because they architect systems where intelligence is distributed across layers of memory, structure, reasoning, and constraint.
If you build AI products, this is your invitation… and your responsibility.
The foundation of intelligence is not inference.
It is context.
In a collaboration with Aakash Gupta.
Must check out his awesome work!
 | A guest post by
|